- Formatting : Whitespace , Naming , Imports , Braces , comparing with the sample , Comments
- Types and generics : Annotation return type , Divergence , Type aliases , Implicit conversions
- Collections : Hierarchy , Application , Style , Performance , Java Collections
- Concurrency : Futures , Collections
- Control Structures : Recursion , Returns , Loops
forand Generators ,requireandassert - Functional Programming : Case Classes as Algebraic Data Types , Option , Pattern Matching , Partial Functions , Deconstruction , Lazy Evaluation , Passing by Name ,
flatMap - Object-oriented programming : Dependency injection , Traits (of Traits) , Visibility , structural typology
- Garbage collection
- Java compatibility
- Twitter Standard Libraries : Futures , Offer / Broker
Scala is not only very efficient, but also a great language. Our experience has taught us to be very careful when using it in our applications in combat conditions. What are the pitfalls? What features should be used and which should be discarded? When can we use « purely functional style » and when should we avoid it? In other words: what do we use on a daily basis to be more effective using this language? This guide tries to convey our experience in short notes, presenting them as a set of best practices.… We use Scala to create high quality services that are distributed systems – our opinion might be biased – but most of the advice here should work seamlessly when porting to other systems. All of this advice is not the ultimate truth, and a slight deviation should be perfectly acceptable.
Scala provides many tools that allow you to summarize your actions. If we type less text, it means that we will have to read less, which means that the source code will be read faster, so the brevity of the code increases its clarity. However, brevity can also be a bad helper, which can have the opposite effect: following correctness, you always need to think about the reader.
A little about the Scala program . You don’t write code in Java, Haskell, or Python; writing a Scala program is different from writing in any of these languages. In order to use a language effectively, you must describe your problems in terms of that language. Nobody forces you to use a program written in Java in Scala, in most cases it will be inferior to the original.
This document is not an introduction to the Scala language; we assume that the reader is familiar with the language. Here are some resources for learning the Scala language:
- Scala school
- Learning Scala
- Learning Scala in Small Bites
This set of articles is a living document that will evolve with our current “best practices,” but the core ideas are unlikely to change: write code that is always easy to read; write universal code, but not at the expense of clarity; use simple language functions that are very powerful, but avoid esoteric functions (especially in the type system). Above all, you always need to find compromises in what you do. Complexity in a language is required in complex implementations because it creates complexity: in reasoning, in semantics, in interactions between system features, and in understanding between your employees. Thus, difficulty is a derivative of complexity — you must always ensure that its usefulness exceeds its value.
And have fun.
Formatting
The specific ways in which you format your code – as long as they’re useful – don’t really matter. By definition, style cannot be good or bad, almost everything is determined by personal preference. However, consistent application of the same formatting rules will almost always increase readability. The reader already familiar with this style does not need to understand yet another set of local conventions or decipher another piece of linguistic grammar.
This is of particular importance to Scala because its grammar has a high level of occurrence. One telling example is method invocation: Methods can be called with “ .”, either using a space, or without parentheses for non-return methods, or for unary methods, with parentheses for the same cases, and so on. Also, the different styles of method calls leave ambiguity in its grammar! Of course, consistently applying a predetermined set of formatting rules will resolve much of the ambiguity for both humans and machines.
We adhere to the [Scala Formatting Rules] (http://docs.scala-lang.org/style/) and additionally the following rules.
Whitespace characters
2 spaces are used for indentation. We try to avoid lines longer than 100 characters. We use one blank line between method, class and object definitions.
Naming
- Use short names for small scopes
- Apply
i,jandksimilar variables in loops - Use long names for large scopes
- External APIs should have long, descriptive names that make sense.
Future.collectinstead ofFuture.all. - Use standard abbreviations and discard esoteric
- Everyone knows
ok,errordefn, but itsfriis not used so often. - Don’t use the same names for different purposes
- Apply
val - Avoid using
`reserved names for overloading. - Use
typinstead of`type` - Use active in the name for side-effect operations
user.activate()instead ofuser.setActive()- Use descriptive names for methods that return values
src.isDefinedinstead ofsrc.defined- Do not prefix getters
get - According to the previous rule: it is better to use
site.countinstead ofsite.getCount - Do not reuse names that are already in the package or in the name of the object
Preferably:
object User { def get(id: Int): Option[User] }instead of
object User { def getUser(id: Int): Option[User] }They are redundant, because when used:
User.getUserit gives no more information thanUser.get.
Import
- Arrange import strings alphabetically
- This makes them easier to identify visually and easier to automate.
- Use curly braces when importing multiple names from a package
import com.twitter.concurrent.{Broker, Offer}- Use underscore when importing more than 6 names
- eg:
import com.twitter.concurrent._
Do not use this sign without consideration, some packages export too many names - When using collections, qualify names when importing
scala.collection.immutableand / orscala.collection.mutable - Mutable and immutable collections have double names. Clarification of names will make it obvious to the reader which variant is being used (for example »
immutable.Map« ) - Don’t use relative imports from other packages
Avoid
import com.twitter import concurrentin favor of a more one-to-one
import com.twitter.concurrent- Place import lines at the top of the file
- The reader can refer to all import lines in one place
Braces
Curly braces are used to create complex expressions (they serve other purposes in the “module language”), where the value of the corresponding expression is the last expression in the list. Try not to use parentheses for simple expressions; write
def square(х: Int) = х*х
.LP instead of
def square(х: Int) = {
х * х
}
.LP, although it might be attractive to distinguish the method body syntactically. The first option has less clutter and is easier to read. Avoid unnecessary syntactic constructs unless further specified.
Comparison with the sample
Use pattern matching in function definitions when needed; Instead of
list map { item =>
item match {
case Some(x) => x
case None => default
}
}
better to write like this
list map {
case Some(x) => x
case None => default
}
It can be seen that the elements of the list are now displayed more clearly – there is no need to further clarify anything.
Comments (1)
Use ScalaDoc to provide API documentation. Use the following style:
/**
* ServiceBuilder builds services
* ...
*/
instead of the standard ScalaDoc style:
/** ServiceBuilder builds services
* ...
*/
Don’t go for ASCII art or other visual decoration. Document the API, but don’t add unnecessary comments. If you add comments to explain the behavior of your code, first ask yourself if the code could be rewritten to make it obvious what it does. Better to prefer “Obviously it works” instead of “It works, obviously” (quoted by Anthony Hoare).
(note interpreter: « There are two methods of creating software One of them – to make the program so simple that, obviously, there are no disadvantages, and others, to make the app so complex that it can not see obvious shortcomings…. » – Anthony Hoare lecture excerpt, Turing Prize )
Types and generic types
The main purpose of the type system is to identify programming errors. The type system effectively provides some form of static checking, which allows us to get a certain set of immutable parameters about our code that the compiler can check. The type system provides other benefits, of course, but error checking is its primary purpose.
The use of the type system should reflect this purpose, but we must also keep the reader in mind: judicious use of types can serve to increase clarity. To overcomplicate everything is to confuse others.
Scala’s powerful type system is the result of the combined efforts of various academic experiences and developments (for example, [Scala Type System Programming] (http://apocalisp.wordpress.com/2010/06/08/type-level-programming-in- scala /)). While this is a fascinating academic article, these techniques rarely find useful application in actual application code. They can be avoided.
The return type of annotations
While Scala allows you to omit them, such annotations provide good documentation: this is especially important for public methods. Where the return type of a method is obvious, they can be omitted.
This is especially important when instantiating Mixins objects, as the Scala compiler creates a singleton type for them. For example, makein the example:
trait Service
def make() = new Service {
def getId = 123
}
has no return type Service; the compiler creates Object with Service{def getId: Int}. Instead of using explicit annotation:
def make(): Service = new Service{}
Currently, an author can mix many traits without changing the public type make, making it easier to manage backward compatibility.
Divergence
Discrepancy occurs when generic types are combined and subtyped. They define how subtyping of type contained relates to subtyping of type container . Because Scala has some convention for commenting, authors of shared libraries – especially collections – should actively write comments. Such comments are important for the convenience of working with common code, but incorrect comments can be dangerous.
Invariants are an advanced but necessary component of Scala’s type system, and should be used widely (and correctly) as they aid the application in subtyping.
Immutable collections must be covariant . Methods that receive a contained type must be “downgraded” to an appropriate collection:
trait Collection[+T] {
def add[U >: T](other: U): Collection[U]
}
Mutable collections must be invariant . Covariance is usually meaningless with mutable collections. Consider
trait HashSet[+T] {
def add[U >: T](item: U)
}
and the following type hierarchy:
trait Mammal
trait Dog extends Mammal
trait Cat extends Mammal
Let’s say we now have a hash collection of Dog objects
val dogs: HashSet[Dog]
create a hash collection of Mammals and add a Cat object to the collection
val mammals: HashSet[Mammal] = dogs
mammals.add(new Cat{})
Now this hash collection is not a collection of Dog objects 🙂
(translator’s note: More about covariance and contravariance )
Type aliases
Use type aliases when they allow you to conveniently name or clarify purposes, but do not mangle types that are already obvious.
() => Int
this entry is clearer than
type IntMaker = () => Int
IntMaker
since it is shorter and a generic type is used, however
class ConcurrentPool[K, V] {
type Queue = ConcurrentLinkedQueue[V]
type Map = ConcurrentHashMap[K, Queue]
...
}
more useful because it conveys purpose and improves brevity.
Don’t use subclassing when the alias does the same
trait SocketFactory extends (SocketAddress => Socket)
SocketFactory this is the function that creates Socket. Using a pseudonym
type SocketFactory = SocketAddress => Socket
more correct. We can now provide functional identifiers for type values SocketFactoryand also use function composition:
val addrToInet: SocketAddress => Long
val inetToSocket: Long => Socket
val factory: SocketFactory = addrToInet andThen inetToSocket
Type aliases are associated with higher names in the hierarchy using package objects:
package com.twitter
package object net {
type SocketFactory = (SocketAddress) => Socket
}
Note that aliases are not new types — they are equivalent to syntactically replacing a type with a new name.
Implicit conversions
Implicit conversions are a powerful feature of the type system, but they should be used where needed. They complicate the transformation rules with laborious – if simple, then lexical comparison – to understand what is really going on. Typically, implicit conversions are used in the following situations:
- Extending or Adding Scala-Style Collections
- Adapting or extending an object (template “pimp my library”)
- To improve type safety by providing a limited set of data
- To provide data of type (typeclassing)
- For
Манифестов
If you really want to use implicit conversions, first ask yourself if there is a way to achieve the same goal without their help.
Do not use implicit conversions to make automatic conversions between similar data types (for example, converting a list to a stream); this is best done explicitly because types have different semantics and the reader should beware of such implementations.
Collections
Scala has a versatile, rich, powerful, and beautifully designed collection library; collections are high-level implementations and they represent a large set of different operations. A lot of actions on collections and transformations on them can be expressed succinctly and clearly, but careless use of functions can lead to the opposite result. Every Scala programmer should read the Collections design document ; it will give you more understanding when working with the collection library in Scala.
Always use the simplest collection that suits your needs.
Hierarchy
Library collections are very large, in addition to a complex hierarchy – the root of which is Traversable[T]– there immutableand mutablethe options for most collections. Despite the complexity, the following diagram contains important differences between immutableand mutablehierarchies
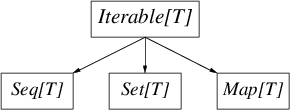
Iterable[T]is any collection whose elements can be iterated over, it has a method iterator(as well as a method foreach). Seq[T]– a collection whose elements are sorted , Set[T]– is an analogue of a mathematical set (an unordered collection of unique elements), and Map[T]– which is an unsorted associative array.
Application
It is preferable to use immutable collections. * They are applicable in most cases, and make the program simpler and more transparent, and also thread safe.
Use
mutablenamespace explicitly. * Don’t importscala.collection.mutable._but reference toset, better to do like thisimport scala.collections.mutable val set = mutable.Set ()
so it becomes clear that the mutable option is being used
Use the standard constructor for collections. * Whenever you need an ordered sequence (and not necessarily a linked list), use a constructor
Seq()or something similar:val seq = Seq (1, 2, 3) val set = Set (1, 2, 3) val map = Map (1 -> “one”, 2 -> “two”, 3 -> “three”)
This style decouples the semantics of a collection from its implementation, allowing the collection library to use the most appropriate type: if you want Map, you do n’t have to use a Red-Black Tree . In addition, standard constructors will often use specialized views: for example, they Map()will use an object with 3 fields for objects with 3 keys ( Map3).
In conclusion, to the above: in your own methods and constructors, try to use the most generic collection possible . Usually it comes down to one of the following: Iterable, Seq, Set, or Map. If your method needs consistency, use Seq[T]instead List[T].
Style
Functional programming calls for chaining immutable collections to achieve the desired result. This often leads to very short solutions, but it can also be confusing to the reader – it is often difficult to understand the intent of the author, or to keep track of all the intermediate results that are implied. For example, suppose we want to count votes for different programming languages from a certain set (language, number of votes); showing them, in descending order of the number of votes, we could write:
val votes = Seq(("scala", 1), ("java", 4), ("scala", 10), ("scala", 1), ("python", 10))
val orderedVotes = votes
.groupBy(_._1)
.map { case (which, counts) =>
(which, counts.foldLeft(0)(_ + _._2))
}.toSeq
.sortBy(_._2)
.reverse
this is short and correct, but almost any reader needs time to reconstruct the original intentions of the author. A strategy that aims to clarify the decision using intermediate results and parameters :
val votesByLang = votes groupBy { case (lang, _) => lang }
val sumByLang = votesByLang map { case (lang, counts) =>
val countsOnly = counts map { case (_, count) => count }
(lang, countsOnly.sum)
}
val orderedVotes = sumByLang.toSeq
.sortBy { case (_, count) => count }
.reverse
the code is almost as concise, but much more clearly describes the transformations that take place (thanks to the named intermediate values) and the data structures that the program works with (named parameters). If you’re worried about clogging up the namespace while applying this style, use expression grouping with {}:
val orderedVotes = {
val votesByLang = ...
...
}
Performance
High-level collection libraries (as usual with high-level constructs) make performance measurement more difficult: the further you stray from directing specific commands to the computer – in other words, imperative style – the harder it is to predict the exact performance value of a piece of code. It is usually easier to justify correctness, however; also improves the readability of the code. With Scala, the situation is complicated by the Java runtime; Scala hides boxing / unboxing operations from us, but they can seriously impact performance or have the opposite effect.
Before focusing on the low-level details, make sure to use the collection that is appropriate for the occasion. Make sure your data structure doesn’t have unexpected asymptotic complexity. Difficulties arising during the work for different Scala collections are described here .
The first rule of performance optimization is to understand why your application is slow. Do not act without looking back; profile your ^ Yourkit is a good profiler] application before proceeding . Focus on heavy loops and large data structures first. Excessive optimization efforts are usually wasted. Remember Knuth’s principle: « Premature optimization is the root of all evil. »
It is often advisable to use low-level collections in situations where you need better performance or have an efficiency reserve for the future. Use arrays instead of lists for large sequences (an immutable Vectorcollection provides a similar interface for arrays); and use buffers instead of sequencing when performance issues are at stake.
Java Collections
Use scala.collection.JavaConvertersto interact with Java collections. This collection implicitly adds conversion methods asJavaand asScala. Using them ensures that such conversions are explicit, helping the reader:
import scala.collection.JavaConverters._
val list: java.util.List[Int] = Seq(1,2,3,4).asJava
val buffer: scala.collection.mutable.Buffer[Int] = list.asScala
Parallelism
Today’s services are highly concurrent — servers perform 10,000 to 100,000 concurrent operations — and their processing implies complexity, which is a central theme in reliable software systems.
Threads are a means of expressing concurrency: they give you independent execution contexts with shared shared memory that is managed by the operating system. However, creating threads is a costly operation in Java and must be managed, usually using pools. This creates additional complexity for the programmer, and also has a high degree of coherence: it is difficult to separate the logic of the application from the underlying resources it uses.
This complexity is especially noticeable when creating services that have a high degree of parallelism: each incoming request result in the set of all requests for each level of the system. In such systems, thread pools must be organized in such a way that they are balanced depending on the number of requests at each level: the mess in one thread pool negatively affects others.
A reliable system must also watch out for timeouts and failures, both of which require additional « control » of flows, thus complicating the problem even further. Note that if the threads were cheaper, then these problems would be reduced: the need for pools, thread timeouts could be discarded, and no additional resources for management would be required.
Thus, resource management compromises modularity.
Futures
Use futures to control concurrency. They allow you to decouple parallel operations from resource management: for example, Finagle bundles parallel operations into multiple threads in an efficient way. Scala has a lightweight closure syntax, so futures introduces a bit of syntactic sugar; and they are becoming more and more popular among programmers.
Futures allow the programmer to declaratively express parallel computations, to compose, and control the source of the error. These qualities have convinced us that they are particularly well suited for use in functional programming languages where this style is encouraged.
Modify futures instead of creating your own. Futures allow you to catch an error, identify a rejection signal, and let the programmer not think about releasing the memory model in Java. A careful programmer can write the following solution for an RPC sequence of 10 elements and then print the results:
val p = new Promise[List[Result]]
var results: List[Result] = Nil
def collect() {
doRpc() onSuccess { result =>
results = result :: results
if (results.length < 10)
collect()
else
p.setValue(results)
} onFailure { t =>
p.setException(t)
}
}
collect()
p onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
The programmer must ensure that RPC errors will propagate further by integrating code and control flow; even worse, this code is wrong! Without declaring a variable results, we cannot guarantee that it resultscontains the previous value at each iteration. The Java memory model is not as simple as it sounds, but luckily we can avoid all of these mistakes with a declarative style:
def collect(results: List[Result] = Nil): Future[List[Result]] =
doRpc() flatMap { result =>
if (results.length < 9)
collect(result :: results)
else
result :: results
}
collect() onSuccess { results =>
printf("Got results %s\n", results.mkString(", "))
}
We use flatMapin a sequence of operations and store the result in a list while the computation is in progress. This is the general idea of functional programming languages implemented in Futures. This requires fewer blanks, fewer errors, and better readability.
Use Futures combinators . Future.select, Future.joinAnd Future.collectimplement common patterns when working on multiple Futures, which should be united.
Collections
Many opinions, subtleties, dogmas, fear, uncertainty and doubt are associated with parallel collections. In most practical situations, they are not a problem: Always start with the simplest, most nondescript, and standard collection that will serve the purpose. Don’t use a parallel collection before you know that the synchronized version of the collection is not working: the JVM has modern mechanisms to make synchronization a cheap operation, so their efficiency may surprise you.
If you need to use an immutable collection, use it – it’s completely transparent, so it’s very easy to think about them in the context of parallel computing. Changes to immutable collections are usually done by updating the reference to the current value (in varcell or AtomicReference). Care must be taken to apply this correctly: atoms must be re-declared, and переменныеmust be declared on the fly in the order they are declared in other threads.
Mutable concurrent collections have complex semantics and take advantage of the intricacies of the Java memory model, so make sure you understand the implications – especially when propagating updates – before you start using them. Synchronous collections are also a good option: operations such as getOrElseUpdatecannot be correctly implemented for parallel collections, and the creation of complex collections is especially error-prone.
Control Structures
Functional-style programs tend to require fewer traditional control structures, and code is better read when it is written in a declarative style. This usually means splitting your logic into several small methods or functions, and glueing them together with matchexpressions. Functional programs also tend to be more expression-oriented: conditional branches for values of the same type, for (..) yieldcomplement computation, and recursion are common.
Recursion
Wording the problem in terms of recursion usually simplifies it , and if tail-recursion optimization is applied (which can be checked with annotation @tailrec), the compiler converts the code into a regular loop.
Consider a fairly standard imperative fix-down heap implementation :
def fixDown(heap: Array[T], m: Int, n: Int): Unit = {
var k: Int = m
while (n >= 2*k) {
var j = 2*k
if (j < n && heap(j) < heap(j + 1))
j += 1
if (heap(k) >= heap(j))
return
else {
swap(heap, k, j)
k = j
}
}
}
Each time we enter the loop, we work with the state of the previous iteration. The value of each variable is the result of evaluating a function of a particular branch of execution, and the value is returned in the middle of the loop if the correct result was found (an attentive reader will find similar arguments in Dijkstra’s « On the Harm of the Go To Statement » ).
Consider the implementation of (tail) recursion [1] :
@tailrec
final def fixDown(heap: Array[T], i: Int, j: Int) {
if (j < i*2) return
val m = if (j == i*2 || heap(2*i) < heap(2*i+1)) 2*i else 2*i + 1
if (heap(m) < heap(i)) {
swap(heap, i, m)
fixDown(heap, m, j)
}
}
here each iteration starts from scratch , and there are no reference fields: there are enough invariants. This is much easier to reason about and easier to read. There is no performance penalty: since the method is tail-recursive, the compiler puts it in a regular loop.
Returning values
This does not mean that imperative structures are useless. In many cases, they are well suited for terminating computations instead of conditional jumps for all possible terminations of computations: after all, in the above fixDown, it is returnused to terminate early if we are at the end of the heap.
Returns can be used to reduce branching and set invariants. It helps the reader by reducing nesting and makes it easier to reason about the correctness of the subsequent code (access to an array element cannot occur outside the array). This is especially useful in guard statements:
def compare(a: AnyRef, b: AnyRef): Int = {
if (a eq b)
return 0
val d = System.identityHashCode(a) compare System.identityHashCode(b)
if (d != 0)
return d
// slow path..
}
Use returnto refine and improve readability, but not in the same way as in imperative languages; avoid using it to return calculation results. Instead of
def suffix(i: Int) = {
if (i == 1) return "st"
else if (i == 2) return "nd"
else if (i == 3) return "rd"
else return "th"
}
better to use:
def suffix(i: Int) =
if (i == 1) "st"
else if (i == 2) "nd"
else if (i == 3) "rd"
else "th"
but using an expression matchis better:
def suffix(i: Int) = i match {
case 1 => "st"
case 2 => "nd"
case 3 => "rd"
case _ => "th"
}
Note that use returnscomes at a cost too: when used inside a closure,
seq foreach { elem =>
if (elem.isLast)
return
// process...
}
in bytecode, this is implemented as a pair of catching / throwing exceptions, the use of which in real code affects performance.
Loops forand generators
forprovides a concise and natural way to cycle through data and accumulate it. This is especially useful when many sequences are being processed. The syntax forconflicts with the basic mechanism for allocating and managing closures. This can lead to unexpected costs and ambiguity, for example
for (item <- container) {
if (item != 2) return
}
… LP can throw a runtime error if there is a delay in evaluating container, making it returnnot local!
For these reasons, generally preferred, cause foreach, flatMap, mapand filterdirect – but it is necessary to use forin order to clarify the calculation.
require and assert
requireand assert, both operators are described in the documentation. Both are useful for situations in which the type system cannot determine the desired variant of the type. assert, used for invariants that are assumed in the code (either internal or external), for example
val stream = getClass.getResourceAsStream("someclassdata")
assert(stream != null)
Whereas requireused to represent API contracts:
def fib(n: Int) = {
require(n > 0)
...
}
Functional programming
Programming, focused on the transformation of values ( of value oriented programming ), it has many advantages, especially when used in conjunction with functional programming constructs. This style emphasizes transforming values instead of changing state, which results in relatively simple code, provides constructs that are less subject to change, and as a result, makes it easier to understand. Case classes, pattern matching, deconstruction, type inference, and simple syntax for creating closures and methods are essential elements of this approach.
Case Classes as Algebraic Data Types
Case classes are used to describe algebraic data types (ADTs): they are useful when implementing a large number of data structures and make it possible to write compact code with similar constructs, especially when used in conjunction with pattern matching. The matching engine performs exhaustive analysis, providing even stronger static guarantees.
Use the following pattern when implementing an ADT using case classes:
sealed trait Tree[T]
case class Node[T](left: Tree[T], right: Tree[T]) extends Tree[T]
case class Leaf[T](value: T) extends Tree[T]
type Tree[T]has two constructors: Nodeand Leaf. A type declaration with a modifier sealedallows the compiler to perform an exhaustive analysis, since constructors cannot be added in another source file.
When used in conjunction with pattern matching, such an implementation produces code that is concise and “obviously correct”:
def findMin[T <: Ordered[T]](tree: Tree[T]) = tree match {
case Node(left, right) => Seq(findMin(left), findMin(right)).min
case Leaf(value) => value
}
Despite the fact that the classic application of ADTs is recursive data structures such as trees, the area where they can be used with success is much wider. In particular, using algebraic data types can easily implement the disconnected joins commonly found in state machines.
Option
The Option type is a container that can either be empty ( None) or contain a value ( Some(value)). It provides a safe alternative to use nulland should be applied locally nullwherever possible. Noneand Someare collections (containing no more than one element) and are equipped with collection-specific operations – use them more often!
Instead of
var username: String = null
...
username = "foobar"
should write
var username: Option[String] = None
...
username = Some("foobar")
since this is safer: using the `Option` type provides a static test of the value of` username` for emptiness.
The use of Option in conditionals must be done using the foreach method; instead of
if (opt.isDefined)
operate(opt.get)
write
opt foreach { value =>
operate(value)}
This style may seem odd, but it provides more safety (we are not using a method getthat might throw exceptions) and conciseness. If you need to handle both possibilities, use pattern matching:
opt match {
case Some(value) => operate(value)
case None => defaultAction()
}
but if all that is required is to provide a default value, use the `getOrElse` method
operate(opt getOrElse defaultValue)
Option should not be overused: if there is a meaningful default value – Null Object – it is better to use it. In addition, Option has a convenient constructor for boxing values that can benull
Option(getClass.getResourceAsStream("foo"))
the result of this expression is of type `Option [InputStream]` and will be None if `getResourceAsStream` returns` null`.
Pattern matching
Pattern matching ( x match { ...) is widespread in well-written Scala code: it combines conditional expressions, deconstruction, and typecasting in a single construct. When used correctly, matching improves security and makes your code more readable:
Use pattern matching to implement type switching:
obj match {
case str: String => ...
case addr: SocketAddress => ...
Pattern matching works best in conjunction with deconstruction (for example, if you are matching case classes); instead of
animal match {
case dog: Dog => "dog (%s)".format(dog.breed)
case _ => animal.species
}
better write
animal match {
case Dog(breed) => "dog (%s)".format(breed)
case other => other.species
}
Write your own extractors , but only with an accompanying constructor (apply), otherwise their use may be inappropriate.
Do not use pattern matching for conditional expressions when it makes sense to use default values. Library collections usually provide methods that return Option; avoid
val x = list match {
case head :: _ => head
case Nil => default
}
because
val x = list.headOption getOrElse default
and shorter and more in line with the purpose.
Partial functions
Scala provides a concise syntax for defining partial functions:
val pf: PartialFunction[Int, String] = {
case i if i%2 == 0 => "even"
}
Alternatively, they can be grouped using `orElse`:
val tf: (Int => String) = pf orElse { case _ => "odd"}
tf(1) == "odd"
tf(2) == "even"
Partial functions spill over in many situations and are effectively described using type PartialFunction, for example, as arguments to methods
trait Publisher[T] {
def subscribe(f: PartialFunction[T, Unit])
}
val publisher: Publisher[Int] = ..
publisher.subscribe {
case i if isPrime(i) => println("found prime", i)
case i if i%2 == 0 => count += 2
/* ignore the rest */
}
or in situations where Option would otherwise be required to return a result:
// Attempt to classify the the throwable for logging.
type Classifier = Throwable => Option[java.util.logging.Level]
This can be better expressed using `PartialFunction`:
type Classifier = PartialFunction[Throwable, java.util.Logging.Level]
because this is how the expressions are grouped perfectly:
val classifier1: Classifier
val classifier2: Classifier
val classifier = classifier1 orElse classifier2 orElse { _ => java.util.Logging.Level.FINEST }
Deconstruction
Destructuring bindings is closely related to pattern matching. It uses the same mechanism, but applies where there is no need to choose between multiple choices (which eliminates the possibility of a matching exception). Deconstruction is especially useful when using tuples and case classes.
val tuple = ('a', 1)
val (char, digit) = tuple
val tweet = Tweet("just tweeting", Time.now)
val Tweet(text, timestamp) = tweet
Lazy evaluation
If a valmodifier is specified before the keyword in the Scala code when declaring a field lazy, then the value of this field will be calculated only when it is required. Since fields and methods in Scala are equivalent (apart from the fact that fields are implicitly declared with a modifier private[this]), then
lazy val field = computation()
this is an (approximate) shorthand for
var _theField = None
def field = if (_theField.isDefined) _theField.get else {
_theField = Some(computation())
_theField.get
}
In other words, the results are calculated and remembered. Use lazy fields for these purposes, but avoid using lazy evaluation when laziness comes from semantics. In such cases, it is better to avoid inappropriate actions in order to make the estimate of the cost of operations more obvious and allow you to control side effects more accurately.
Lazy fields are thread safe.
Passing by name
Method parameters can be defined as passed by name, which means they are not bound to a value, but to some computation that can be re-executed. This feature should be used with caution; if the caller of this method expects parameters to be passed by value, then he may be very surprised. This capability is needed to describe domain-specific languages (DSLs) with natural syntax – in particular, new control constructs may look the same as if they were a natural feature of the language.
Use passing by name only in those control constructs, when called, it is obvious that what is being passed to them is a “block”, and not the result of an unexpected calculation. Specify the arguments passed by name only in the last position of the last argument list. When using passing by name, make sure the method has a name that makes it obvious that the argument is passed by name.
If you want the value to be evaluated multiple times, especially if this calculation is accompanied by side effects, you should explicitly use functions:
class SSLConnector(mkEngine: () => SSLEngine)
Your intentions will remain clear and those who use this code will not be surprised.
flatMap
A method flatMapthat combines the methods mapand flattendeserves special attention, since it has not immediately noticeable power and can be very useful. Like its sibling map, it is often available in an unconventional collection such as Futureor Option. His behavior is easy to understand by his signature; for someContainer[A]
flatMap[B](f: A => Container[B]): Container[B]
flatMapcalls a function ffor the elements (or element) of the collection, thus creating new collections, which are finally combined into one. For example, to get all permutations of two dissimilar characters:
val chars = 'a' to 'z'
val perms = chars flatMap { a =>
chars flatMap { b =>
if (a != b) Seq("%c%c".format(a, b))
else Seq()
}
}
which is equivalent to a more concise for-comprehension (which is syntactic sugar for the above):
val perms = for {
a <- chars
b <- chars
if a != b
} yield "%c%c".format(a, b)
flatMap It is often useful when dealing with Option – here it will collapse Option chains into one:
val host: Option[String] = ..
val port: Option[Int] = ..
val addr: Option[InetSocketAddress] =
host flatMap { h =>
port map { p =>
new InetSocketAddress(h, p)
}
}
It can be made even shorter using `for`
val addr: Option[InetSocketAddress] = for {
h <- host
p <- port
} yield new InetSocketAddress(h, p)
The use flatMapfor is Futurediscussed in the futures section .
Object Oriented Programming
Most of Scala’s capabilities are provided by the object system. Scala is a pure language in this sense, because all elements are objects, there is no distinction between primitive types and composite types. Scala also has Mixins that allow for clearer building of modules that can be flexibly assembled at compile time with all the benefits of static type checking.
The main idea behind the mixin system is to avoid the need for traditional dependency building. The culmination of this “component style” of programming is the cake pattern .
Dependency injection
In our experience, we have found that Scala actually removes most of the syntax overhead of “classic” (in the constructor) dependency injection, and we can use that: a clearer description, dependencies are still encoded in the type, and the class construction is so syntactically simple that it becomes imperceptible. It’s boring and simple and it works. Use dependency injection to modularize your program , and in particular prefer composition over inheritance – this will lead to more modular and more testable programs. If a situation arises where inheritance is required, then ask yourself: how would you design a program if the language did not have such a capability as inheritance? The answer may not be so simple.
For dependency injection, traits are usually used,
trait TweetStream {
def subscribe(f: Tweet => Unit)
}
class HosebirdStream extends TweetStream ...
class FileStream extends TweetStream ..
class TweetCounter(stream: TweetStream) {
stream.subscribe { tweet => count += 1 }
}
They are commonly used to implement factories – objects that generate other objects. In this case, it is preferable to use simpler functions instead of specialized type factories.
class FilteredTweetCounter(mkStream: Filter => TweetStream) {
mkStream(PublicTweets).subscribe { tweet => publicCount += 1 }
mkStream(DMs).subscribe { tweet => dmCount += 1 }
}
Traits
Dependency injection does not at all exclude the possibility of using common interfaces , or releasing common code in traits. Quite the opposite – the use of traits is highly recommended for this very reason: several interfaces (traits) can be implemented in a specific class, and the common code can be used in all such classes.
Try to keep your traits short and simple: don’t split functionality between traits, think of them as small pieces that are linked together. For example, imagine you have something that IO can do:
trait IOer {
def write(bytes: Array[Byte])
def read(n: Int): Array[Byte]
}
split the code into two behaviors:
trait Reader {
def read(n: Int): Array[Byte]
}
trait Writer {
def write(bytes: Array[Byte])
}
or combine them together to get what was in IOer: new Reader with Writer… the minimalism of the trait results in simplicity and cleaner modularity.
Visibility
The rock has very expressive visibility modifiers. It is important to use them as they define what the public API is . Public APIs should be limited so that users do not accidentally rely on the implementation of the details and the limit of the author’s ability to change them: they are critical in building good modularity. It is generally much easier to extend public APIs than to shorten them. Bad annotations can also undermine the backward binary compatibility of your code.
private[this]
Class member marked as private,
private val x: Int = ...
visible to all instances of this class (but not subclasses). In most cases, you need one private[this].
private[this] val x: Int = ..
which limits the visibility to a specific instance. The Scala compiler can also translate private[this]to a simple field for access (since access is limited to a statically defined class) which can sometimes help in optimizing performance.
Singleton class
It is common Scala practice to create a singleton class, for example
def foo() = new Foo with Bar with Baz {
...
}
In such situations, visibility can be limited by declaring the return type:
def foo(): Foo with Bar = new Foo with Bar with Baz {
...
}
where the calling foo()portions of the code will be constrained with ( Foo with Bar) on the returned instance.
Structural typing
Don’t use structured types in normal cases. They are convenient and powerful, but unfortunately do not have an efficient JVM implementation. However – for implementation reasons – they provide a very concise expression for writing reflections.
val obj: AnyRef
obj.asInstanceOf[{def close()}].close()
Garbage collection
We spend a lot of time setting up the garbage collector in real code. The garbage collector problems are largely similar to those in Java, although ideologically, Scala code tends to generate more (short-lived) garbage than similar Java code — all a byproduct of the functional style. The garbage collector usually does this without a problem, since short-lived garbage is collected efficiently in most cases.
Before trying to tackle garbage collector performance issues, check out this talk by Attila, which illustrates some of our experience with garbage collector tuning.
In Scala, your only way to alleviate your garbage collector problems is to create less garbage, but don’t go without prior data! Until you do something that clearly makes things worse, use the various Java profiling tools – Our own tools include heapster and gcprof .
Java compatibility
When we write Scala code that is used in Java, we are sure that this feature remained for purely ideological reasons. This usually requires little effort – classes and pure traits are exactly the equivalent of their Java counterparts – but sometimes you need to provide some Java APIs. A good way to get this for your Java library API is to write a unit test in Java (compile only), this will also ensure that the behavior of your Java library remains stable over time, because the Scala compiler can be unstable in this regard.
Traits that implement some functionality are not suitable for direct use in Java: for this, you need to extend the abstract class with the trait.
// Не используется напрямую в Java
trait Animal {
def eat(other: Animal)
def eatMany(animals: Seq[Animal) = animals foreach(eat(_))
}
// А так можно:
abstract class JavaAnimal extends Animal
Twitter standard libraries
The most important standard libraries on Twitter are Util and Finagle . Util should be seen as an extension to the Scala and Java standard library, providing missing functionality and more tailored to a specific implementation. Finagle is our RPC system, the core of distributed system components.
Futures
Futures were discussed briefly in the section on parallel computing . They are the central mechanism for coordinating asynchronous processes and are widespread in our code and in the Finagle core. Futures allow concurrent events to be combined and also make it easier to reason about highly parallel operations. They can be efficiently implemented in the JVM.
Futures on Twitter are asynchronous , so blocking operations — basically any operation — can be suspended while their thread is executing; network I / O and disk I / O, for example, must be handled by the system, which futures themselves provide for the results of these operations. Finagle provides such a system for network I / O.
Futures are simple and straightforward: they wait for the result of a computation that hasn’t finished yet. They are just a placeholder container. The computation may not end, and this must be coded: Future can be in exactly one of 3 states: pending , failed, or completed .
Aside: Composition
Let’s go back to what we mean by composition: combining simple components into more complex ones. The most common example is the composition function: Given the functions f and g , the composition function (g∘f) (x) = g (f (x)) – first the result is obtained using x in f , and then the result of this expression is applied to g – can be written in Scala:
val f = (i: Int) => i.toString
val g = (s: String) => s+s+s
val h = g compose f // : Int => String
scala> h(123)
res0: java.lang.String = 123123123the h function will be composite. This is a new feature that combines f and g .
Futures are a type of collection – a container of 0 or 1 elements – and you will see that they have a standard collection methods (such as map, filter, and foreach). With a Future, the value is deferred, the result of any of these methods is also deferred, in
val result: Future[Int]
val resultStr: Future[String] = result map { i => i.toString }
the function is { i => i.toString }not called until an integer value is available, and the conversion of the collection is resultStralso deferred until that point.
Lists can be collapsed;
val listOfList: List[List[Int]] = ..
val list: List[Int] = listOfList.flatten
and the same can be done for futures:
val futureOfFuture: Future[Future[Int]] = ..
val future: Future[Int] = futureOfFuture.flatten
with futures there is a delay, the implementation flatten– must immediately – return a future that waits for the outer future ( ) to complete and after that the inner ( ) is executed . If the outer future fails, the collapsed future must also fail.Future[Future[Int]]Future[Future[Int]]
Futures (similar to Lists) also have flatMap; Future[A]announcement:
flatMap[B](f: A => Future[B]): Future[B]
which is similar to the combination of mapand flatten, and we can implement it in the following way:
def flatMap[B](f: A => Future[B]): Future[B] = {
val mapped: Future[Future[B]] = this map f
val flattened: Future[B] = mapped.flatten
flattened
}
This is a powerful combination! With the help flatMapwe can define a Future which is the result of two successive futures, the second future is calculated based on the results of the first. Imagine that we would have to do two RPCs to authenticate the user (ID), then we could define a composite operation like this:
def getUser(id: Int): Future[User]
def authenticate(user: User): Future[Boolean]
def isIdAuthed(id: Int): Future[Boolean] =
getUser(id) flatMap { user => authenticate(user) }
An additional advantage of this type of composition is that there is built-in error handling: the future will not return isAuthed(..)if no additional error handling code is written in one of the functions getUser(..)or authenticate(..).
Style
Future methods of the callback (the callback) ( respond, onSuccess, onFailure, ensure) to return a new future, which is linked with its parent. This future is guaranteed to be completed only after its parent completes, which allows us to write like this:
acquireResource() onSuccess { value =>
computeSomething(value)
} ensure {
freeResource()
}
where is freeResource()guaranteed to be executed after computeSomething, allowing emulation of the template try .. finally.
Use onSuccessinstead foreach– it is symmetric for onFailurethis is the best name for a case like this, and allows chaining calls.
Always try to avoid Promiseinstances directly: almost every task can be solved by using predefined combinations. These combinations provide error and failure propagation, and generally encourage a data flow programming style that typically <href = “#Parallelism-Futures”> removes the need for synchronization and ad management.
Code written in the style of tail recursion does not contribute to the leakage of the stack area, allows you to effectively implement loops in the style of data streams:
case class Node(parent: Option[Node], ...)
def getNode(id: Int): Future[Node] = ...
def getHierarchy(id: Int, nodes: List[Node] = Nil): Future[Node] =
getNode(id) flatMap {
case n@Node(Some(parent), ..) => getHierarchy(parent, n :: nodes)
case n => Future.value((n :: nodes).reverse)
}
Futuredefine many useful methods: Use Future.value()and Future.exception()for creating predefined futures. Future.collect(), Future.join()and Future.select()provide combinations that turn many futures into one (for example, they are combined as part of a collect-parse operation).
Refusal
Futures implement a mild waiver form. The call Future#cancel does not directly terminate the computation, but instead sets a trigger signal that can be requested by a process that will ultimately satisfy the future’s requirements. Failure propagates in the opposite direction than the values: the “failure” signal set by the receiving entity propagates to the entity that set the signal. The entity that asserts the signal uses onCancellationand Promiselistens to that signal and acts accordingly.
This means that the meaning of the failure depends on the object that called it, and there is no default implementation. Refusal is just a hint .
Locals
The utility Localprovides a reference cell that is local to a particular future dispatch tree. Setting the value to local makes this value available for any deferred computation on the same thread. They are similar to thread locals, except that they are not used in Java threads, but in the “future threads” tree. For example, in
trait User {
def name: String
def incrCost(points: Int)
}
val user = new Local[User]
...
user() = currentUser
rpc() ensure {
user().incrCost(10)
}
user()in the block ensurewill refer to the value userlocal at the time the callback function is added.
As with streaming locals, Localthey can be very convenient, but should almost always be avoided: make sure the problem cannot be solved by passing data everywhere explicitly, even if it is somewhat cumbersome.
Locals are used effectively in base libraries for very general tasks – working with streams over RPC, transferring monitors, creating a « stack trace » for future callbacks – where any other solution would be too burdensome for users. Locals are almost unsuitable for any other situation.
Offer / Broker
The operation of parallel systems is greatly complicated by the need to coordinate access to shared data and resources. Actors provide one strategy to make things easier: each actor is a sequential process that maintains its own state and resources, and data is communicated by passing messages to other actors. Data exchange requires interaction between actors.
Offer / Broker has three important components. First, the Broker is the first element – that is, you send messages through the Broker and not directly to the actor. Second, Offer / Broker is a synchronous mechanism: communication is synchronized. This means we can use the Broker as a coordination mechanism: when a process asends a message to a process b, both processes and aand bhave the state of the system. And finally, communication can be carried out selectively : the process can offer several different methods of communication, and in the end it will receive exactly one of them.
In order to maintain selective connections (as well as other connections) in general, we must separate the description of the connection from the communication process. This is what it does Offer– it is a constant that describes the connections, in order to perform the communication (acting on the Offer), we synchronize the process through the methodsync()
trait Offer[T] {
def sync(): Future[T]
}
which returns Future[T], which makes it possible to exchange values when a connection occurred.
Broker coordinates the exchange of values through Offers – this is a communication channel
trait Broker[T] {
def send(msg: T): Offer[Unit]
val recv: Offer[T]
}
so when creating two Offers
val b: Broker[Int]
val sendOf = b.send(1)
val recvOf = b.recv
and sendOfand recvOftwo synchronized
// In process 1:
sendOf.sync()
// In process 2:
recvOf.sync()
both Offers will exchange the value 1.
Selective communication is carried out by combining several Offers using Offer.choose
def choose[T](ofs: Offer[T]*): Offer[T]
which gives new Offers, which, when synchronized, receive only one of them ofs– the first of them will become available for further actions. When there are several of them available at the same time, one of them is chosen at random.
The object Offerhas a number of one-time Offers that are used to combine the Offer with the Broker.
Offer.timeout(duration): Offer[Unit]
this is an Offer that is activated after the transmission of the given duration. Offer.nevernever gets the given value, and Offer.const(value)immediately gets the given value. They are useful for aggregation when selective linking is used. For example, to use a time-delayed send operation:
Offer.choose(
Offer.timeout(10.seconds),
broker.send("my value")
).sync()
It looks tempting when comparing Offer / Broker to SynchronousQueue , but they differ in small but important details. Offers can be structured in such a way that such queues simply do not exist. For example, consider a set of queues represented as Broker:
val q0 = new Broker[Int]
val q1 = new Broker[Int]
val q2 = new Broker[Int]
Now let’s create a shared read queue:
val anyq: Offer[Int] = Offer.choose(q0.recv, q1.recv, q2.recv)
anyqis the Offer that will be read from the first available queue. Note that this anyqis still synchronized – we also have the main queue. Such composition is simply not possible with the use of queues.
Example: Simple Connection Pool
Connection pools are very common in network applications and they are often difficult to implement – for example, it is often desirable to have latency when requesting from a pool, since different clients have different request latencies. The pools themselves are simple: we maintain queues of connections, and we serve pending objects as soon as they arrive. With traditional synchronization primitives, this usually means keeping two queues: one waiting (when they have no connections), and one of the connections (when there are no waiting ones).
Using Offer / Broker, we can express this quite naturally:
class Pool(conns: Seq[Conn]) {
private[this] val waiters = new Broker[Conn]
private[this] val returnConn = new Broker[Conn]
val get: Offer[Conn] = waiters.recv
def put(c: Conn) { returnConn ! c }
private[this] def loop(connq: Queue[Conn]) {
Offer.choose(
if (connq.isEmpty) Offer.never else {
val (head, rest) = connq.dequeue
waiters.send(head) { _ => loop(rest) }
},
returnConn.recv { c => loop(connq enqueue c) }
).sync()
}
loop(Queue.empty ++ conns)
}
loopwill always be a deal to be able to reestablish communication, but only Offer can send a message when the queue is not empty. Using persistent queues simplifies further considerations. Interaction with the pool goes through Offer, so if the caller wants to use the timeout, he can do it using combinators:
val conn: Future[Option[Conn]] = Offer.choose(
pool.get { conn => Some(conn) },
Offer.timeout(1.second) { _ => None }
).sync()
No additional gestures are required to implement timeouts, this is due to the semantics of Offers: if selected Offer.timeout, Offer no longer needs to receive information from their pool – the pool and the calling function cannot simultaneously receive and send data, especially for ожидающихBroker.
Example: Sieve of Eratosthenes
It is often useful – and sometimes it makes life much easier – to represent parallel programs as a set of sequential processes that interact synchronously. Offers and Brokers provide a set of tools to make this simple and consistent. Indeed, their application goes beyond what might be considered « classic » concurrency problems — parallel programming (with Offers / Broker) is a useful structured tool, just like subroutines, classes, and modules.
One of these examples is the Sieve of Eratosthenes , which can be thought of as sequential filtering of streams of integers. First, we must have a source of integers:
def integers(from: Int): Offer[Int] = {
val b = new Broker[Int]
def gen(n: Int): Unit = b.send(n).sync() ensure gen(n + 1)
gen(from)
b.recv
}
integers(n)it just Offer all consecutive integers starting with n. Then you need to filter:
def filter(in: Offer[Int], prime: Int): Offer[Int] = {
val b = new Broker[Int]
def loop() {
in.sync() onSuccess { i =>
if (i % prime != 0)
b.send(i).sync() ensure loop()
else
loop()
}
}
loop()
b.recv
}
filter(in, p)returns Offer, which fetches a set of primes pfrom in. In the end we compose our sieve:
def sieve = {
val b = new Broker[Int]
def loop(of: Offer[Int]) {
for (prime <- of.sync(); _ <- b.send(prime).sync())
loop(filter(of, prime))
}
loop(integers(2))
b.recv
}
loop()it works simply: it reads the next (prime) number from of, then applies a filter ofthat pulls out that number. Since loop– this is recursion, then by filtering successively prime numbers, we get our sieve. We can now print the first 10,000 primes:
val primes = sieve
0 until 10000 foreach { _ =>
println(primes.sync()())
}
In addition to being done with simple, basic ingredients, this approach gives you a sieve: you don’t need a priori information, calculate the set of primes you need, further increasing modularity.


